L'HyperText Transfer Protocol (HTTP)
HTTP & HTTPS
HTTP est le protocol utilisé n'importe quand lorsque l'on visite un site web. L'HTTP est pourvu de plusieurs règles utilisées pour communiquer avec les serveurs web pour la transmission des données des pages (l'HTML, les images, etc...) HTTPS est la version sécurisée de l'HTTP. Les données sont chiffrées de façon à ce que personne ne puisse visionner celles que vous recevez & envoyez. Il donne également l'assurance de communiquer avec le bon serveur web et non pas une usurpation.
Les requêtes & réponses
Lorsque l'on visite un site web, le navigateur doit faire une requête au serveur web pour pouvoir télécharger l'HTML, les images, etc... Avant cela, on doit dire au navigateur où et comment accéder à ces ressources : c'est là que l'URL entre en jeu.
L'URL : son devoir
L'URL est l'instruction au navigateur sur la façon d'accéder aux ressources sur Internet. Le schéma ci-dessous explique cela :
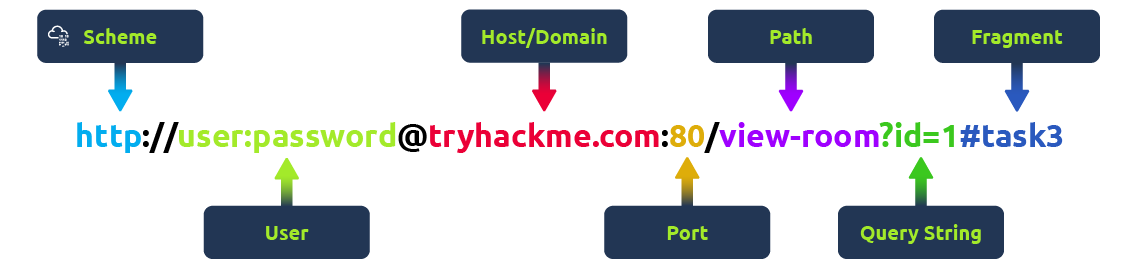
- Scheme : Il indique quel protocole utiliser pour accéder à la ressource telle que HTTP, HTTPS, FTP...
- User : Certains services nécessitent une authentification pour se connecter, cette indication est inscrite dans l'URL
- Host : Le nom de domaine ou l'adresse IP du serveur auquel vous souhaitez accéder.
- Port : Le port utilisé, généralement 80 pour HTTP et 443 pour HTTPS, mais il peut être hébergé sur n'importe quel port entre 1 et 65535.
- Path : Le nom du fichier ou l'emplacement de la ressource à laquelle on souhaite accéder.
- Query String : Des bits supplémentaires d'informations qui peuvent être envoyés au chemin demandé. Par exemple, /blog?id=1 dirait au blog le chemin que l'on souhaite recevoir, ici l'article de blog avec l'ID 1.
- Fragment : Il s'agit d'une référence à un emplacement sur la page effectivement demandée. Celui-ci est couramment utilisé pour les pages à contenu long et peut avoir une certaine partie de la page directement liée à elle, de sorte qu'il est visible pour l'utilisateur dès qu'il accède à la page.
Les méthodes HTTP
Les méthodes HTTP sont un moyen pour le client d'afficher l'action prévue lors d'une requête HTTP. Il existe de nombreuses méthodes HTTP,cependant voici les plus courantes :
- GET : Ceci est utilisé pour obtenir des informations à partir d’un serveur Web.
- POST : Ceci est utilisé pour soumettre des données au serveur Web et potentiellement créer de nouveaux enregistrements.
- PUT : Ceci est utilisé pour soumettre des données à un serveur Web afin de mettre à jour les informations.
- DELETE : Ceci est utilisé pour supprimer des informations/enregistrements d’un serveur Web.
Les codes d'état
Les codes d'état correspondent aux réponses données par un serveur HTTP. La première ligne de la réponse contient toujours un code d'état informant le client du résultat de sa requête et éventuellement de la manière de la gérer.
| Code d'état | Description |
|---|---|
| 100-199 | Réponses aux informatiions |
| 200-299 | Succès |
| 300-399 | Redirection |
| 400-499 | Erreurs client |
| 500-599 | Erreurs serveur |
Les codes courants
| Code d'état | Description |
|---|---|
| 200 | Demande complétée avec succès |
| 201 | Une ressource a été créée |
| 301 | Redirection du client vers une nouvelle page |
| 400 | Indication manquante dans la demande |
| 401 | Non autorisé |
| 403 | Interdit - pas d'autorisation d'accès |
| 404 | Page introuvable ou inexistante |
| 405 | Méthode non autorisée |
| 500 | Erreur de service interne |
| 503 | Service indisponible |
Les en-têtes
Les en-têtes sont des bits de données supplémentaires que l'on peut envoyer au serveur Web lors de requêtes. Bien qu'aucun en-tête ne soit strictement requis lors d'une requête HTTP, on aura du mal à afficher correctement un site Web.
Les en-têtes de requête courants
Ce sont des en-têtes envoyés par le client (généralement le navigateur) au serveur :
Hôte : certains serveurs Web hébergent plusieurs sites Web. Ainsi, en fournissant les en-têtes d'hôte, on peut lui indiquer celui dont on a besoin, sinon on reçoit simplement le site Web par défaut pour le serveur.
Agent utilisateur : il s'agit du logiciel de navigation et de son numéro de version, indiquant au serveur Web que le logiciel de navigation l'aide à formater le site Web correctement pour le navigateur. Certains éléments HTML, JavaScript et CSS ne sont également disponibles que dans certains navigateurs.
Longueur du contenu : lors de l'envoi de données à un serveur Web, par exemple dans un formulaire, la longueur du contenu indique au serveur Web la quantité de données à attendre dans la requête Web. De cette façon, le serveur peut s'assurer qu'il ne manque aucune donnée.
Accept-Encoding : indique au serveur Web quels types de méthodes de compression le navigateur prend en charge afin que les données puissent être réduites pour la transmission sur Internet.
Cookie : données envoyées au serveur pour aider à mémoriser des informations.
Les en-têtes de réponse courants
Ce sont les en-têtes qui sont renvoyés au client par le serveur après une requête.
Set-Cookie : informations à stocker qui sont renvoyées au serveur Web à chaque demande.
Cache-Control : combien de temps faut-il stocker le contenu de la réponse dans le cache du navigateur avant qu'il ne le demande à nouveau.
Content-Type : cela indique au client quel type de données est renvoyé, c'est-à-dire HTML, CSS, JavaScript, Images, PDF, Vidéo, etc. En utilisant l'en-tête content-type, le navigateur sait alors comment traiter les données.
Encodage du contenu : quelle méthode a été utilisée pour compresser les données afin de les rendre plus petites lors de leur envoi sur Internet.
Sources
Ce cours s'inspire (et utilise les images) de TryHackMe.com de la chambre "HTTP in detail" :